Swarm
Swarm is an open-source project designed to extract data published by administrative units in Flanders and republish it as linked data.
It takes advantage of the Flemish government’s open data initiative, which motivates local administrations to publish their decisions as linked open data since 2019.
Largely inspired by a similar existing project, it’s not intended to replace any existing tools; I use it primarily as a sandbox for trying out new ideas in data extraction and processing. For production-level work, I’d strongly recommend using a more reliable solution.
How It Works
Administrative units publish their decisions and meeting notes as RDFa annotated html. Swarm scrapes this data, processes it, and republishes it in a usable format.
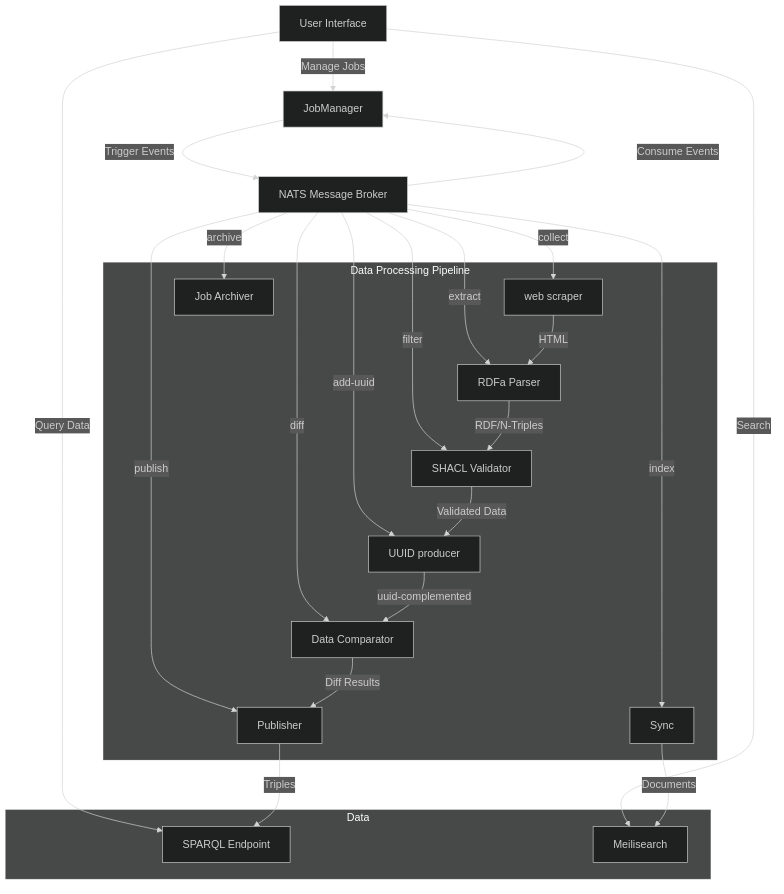
Swarm works with configurable & schedulable jobs (called job definitions), each made up of a series of tasks, and each task is a microservice with a specific responsibility, communicating through events via a NATS message broker.
The primary data processing pipeline consists of the following steps:
collect Scrapes html pages
extract Parses RDFa annotations and converts them into N-Triples
filter Applies shacl shapes to validate and filter the data
add-uuid Enrich RDF subjects with an uuid
diff Compares extracted data with the previous successful job to calculate the delta
publish Insert new triples and remove outdated ones in the triplestore
index Convert and upsert meilisearch documents based on a config
archive Flag the previous job as archived and ready for deletion
Jobs can be scheduled using cron expressions, and the entire system is adaptable to other domains beyond administrative units data.
Swarm also has a dedicated microservice called sync-consumer, that lets third parties consume the extracted data without having to run their own Swarm instance; when a job finishes successfully, the system generates an archive containing the new triples to insert, the triples to delete, and the intersection with the previous job (for initial sync), making it straightforward to keep external triplestores in sync.
This feature was not well tested, so if you’d like to try it, please contact me.
Swarm is developed in Rust, but other languages can be used. For example, the filter step is written in Java.
Swarm uses Virtuoso as its triplestore and Meilisearch for indexing, because it’s fast and offers a great developer experience. Job and task metadata are stored in MongoDB, since that data doesn’t really benefit from being stored as semantic data. This setup keeps the pipeline simpler and faster, but I might revisit this choice if a good reason to use linked data for the metadata comes up in the future.
Custom Components
Swarm is a handmade project that relies on custom components:
These components are not intended for production use due to their experimental nature.
Get started:
Next steps
- Use the data to explore fine-tuning AI models.
Write a parser for Microdata- Create a new job definition to scrape websites annotated with the microdata parser
Request for Removal
If you identify personal or sensitive data sourced from your website and would like it to be removed, please contact me. I will review your request and take appropriate action without delay.